

Data ikke grupperte eksempler og trening løst

- 956
- 36
- Prof. Theodor Gran
De Ikke -grupperte data De er de som, hentet fra en studie, er ennå ikke organisert av klasser. Når det er et håndterbart antall data, vanligvis 20 eller mindre, og det er få forskjellige data, kan de behandles som ikke gruppert og trekke ut verdifull informasjon fra dem.
De ikke -grupperte dataene kommer som fra undersøkelsen eller studien som er utført for å få dem og mangler derfor behandling. La oss se på noen eksempler:
Figur 1. Ikke -grupperte data kommer direkte fra noen studier og har ikke blitt klassifisert. Kilde: Pxhere. -Resultater av en intellektuell koeffisient CI -eksamen hos 20 tilfeldige studenter fra et universitet. Dataene som ble oppnådd var følgende:
119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112.106
-Alder på 20 ansatte i en veldig populær kafeteria:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 19, 22, 27, 29, 23, 20
-De gjennomsnittlige endelige merknadene til 10 elever i en matematikklasse:
3.2; 3.1; 2,4; 4.0; 3.5; 3.0; 3.5; 3.8; 4.2; 4.9
[TOC]
Dataegenskaper
Det er tre viktige egenskaper som kjennetegner et sett med statistiske data er gruppert eller ikke, som er:
-Posisjon, som er tendensen til dataene som skal grupperes rundt visse verdier.
-Spredning, En indikasjon på hvor spredt eller formidlet er dataene rundt en viss verdi.
-Form, Det refererer til måten dataene distribueres på, som kan sees når en graf over dem er konstruert. Det er veldig symmetriske og også partiske kurver, enten til venstre eller til høyre for en viss sentral verdi.
For hver av disse egenskapene er det en rekke tiltak som beskriver dem. Når de er oppnådd, gir de oss et panorama av dataatferd:
-De mest brukte posisjonstiltakene er aritmetisk gjennomsnittlig eller ganske enkelt medium, median og mote.
-I spredningen brukes rekkevidden, varians og standardavvik ofte, men de er ikke de eneste spredningstiltakene.
Kan tjene deg: homotecia-Og for å bestemme skjemaet, blir gjennomsnittet og medianen sammenlignet gjennom skjevhet, som det vil bli sett snart.
Beregning av gjennomsnitt, median og mote
-Det aritmetiske gjennomsnittet, Også kjent som gjennomsnitt og betegnet som x, beregnes det som følger:
X = (x1 + x2 + x3 +... xn) / n
Hvor x1, x2,.. . xn, er dataene og n er summen av dem. I summering av sum er det:

-Medianen Det er verdien som vises midt i en ordnet rekke data, så for å få dem, er det nødvendig å bestille dataene først.
Hvis antall observasjoner er rare, er det ikke noe problem å finne midtpunktet i settet, men hvis vi har et par data, blir de to sentrale dataene søkt og gjennomsnittet.
-Mote Det er den vanligste verdien som er observert i datasettet. Det eksisterer ikke alltid, siden det er mulig at ingen verdi gjentas oftere enn en annen. Det kan også være to data med like frekvens, i så fall er det snakk om en to-modal distribusjon.
I motsetning til de to foregående tiltakene, kan mote brukes med kvalitative data.
La oss se hvordan disse posisjonstiltakene beregnes med et eksempel:
Løst eksempel
Anta at du vil bestemme det aritmetiske gjennomsnittet, median og mote i eksemplet som ble foreslått i begynnelsen: i alderen 20 ansatte i en kafeteria:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 19, 22, 27, 29, 23, 20
De halv Det beregnes ganske enkelt ved å legge til alle verdiene og dele med n = 20, som er det totale antallet data. Denne måten:
Kan tjene deg: proporsjonalitetsrelasjoner: konsept, eksempler og øvelserX = (24 + 20 + 22 + 19 + 18 + 27+ 25 + 19 + 27 + 18 + 21 + 22 + 23 + 21+ 19 + 22 + 27+ 29 + 23+ 20) / 20 =
= 22.3 år.
Å finne median Det er nødvendig å bestille datasettet først:
18, 18, 19, 19, 19, 20, 20, 21, 21, 22, 22, 22, 23, 23, 24, 25, 27, 27, 27, 29
Som det er et par data, blir de to sentrale dataene, fremhevet med fet skrift, tatt og gjennomsnittet. Fordi begge er 22, er medianen 22 år.
Til slutt mote Det er det faktum som gjentas mest eller at hvis frekvens er større, er dette 22 årene.
Rekkevidde, varians, standardavvik og skjevhet
Området er ganske enkelt forskjellen mellom hoved- og minst av dataene og lar deres variasjon raskt sette pris på. Men fra hverandre er det andre spredningstiltak som gir mer informasjon om datadistribusjon.
Varians og standardavvik
Variansen er betegnet som S og beregnes ved uttrykk:
^2n)
^2n-1)
For å tolke resultatene med rette, er standardavviket slik som kvadratroten til variansen, eller også standard kvasi-avvik, definert, som er kvadratroten til kvasivariansen:
^2n)
^2n-1) Partiskhet
Partiskhet
Det er sammenligningen mellom gjennomsnittlig X og median Med:
-Ja med = media x: dataene er symmetriske.
-Når x> med: partisk til høyre.
-Og hvis x < Med: los datos sesgan hacia la izquierda.
Trening løst
Finn gjennomsnittlig, median, mote, rangering, varians, standardavvik og skjevhet for resultatene av en intellektuell koeffisientundersøkelse av 20 studenter fra et universitet:
Kan tjene deg: matematiske funksjoner119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112, 106
Løsning
Vi vil bestille dataene, siden det vil være nødvendig å finne medianen.
106, 106, 106, 109, 109, 109, 109, 109, 112, 112, 112, 112, 112, 112, 119, 119, 124, 124, 124
Og vi vil legge dem i et bord som følger, for å lette beregningene. Den andre kolonnen med tittelen "Akkumulert" er summen av de tilsvarende dataene pluss forrige.
Denne kolonnen vil lett finne gjennomsnittet, og dele det siste akkumulerte mellom det totale antallet data, slik det er sett på slutten av "Akkumulert" kolonnen:
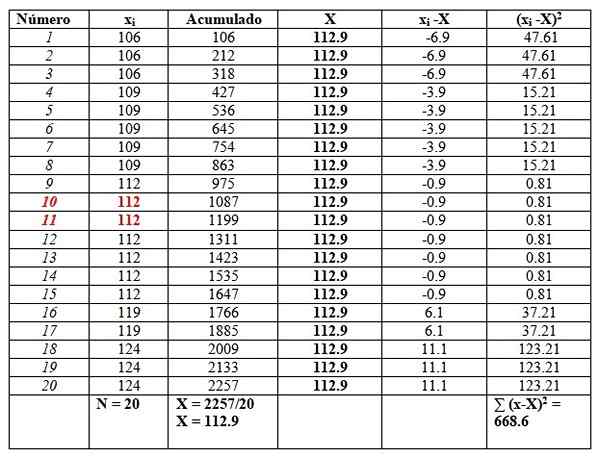
X = 112.9
Medianen er gjennomsnittet av de sentrale dataene som er fremhevet i rødt: nummer 10 og nummer 11. Som det samme er medianen 112.
Endelig er mote verdien som er mest gjentatt og er 112, med 7 repetisjoner.
Når det gjelder spredningstiltak, er området:
124-106 = 18.
Variansen oppnås ved å dele det endelige resultatet av høyre kolonne mellom n:
S = 668.6/20 = 33.42
I dette tilfellet er standardavviket kvadratroten til variansen: √33.42 = 5.8.
På den annen side er verdiene til kvasivarien og kvasi -standardavviket:
sc= 668.6/19 = 35.2
Standard kvasi-avvik = √35.2 = 5.9
Endelig er skjevhet litt til høyre, siden gjennomsnittet 112.9 er større enn median 112.
Referanser
- Berenson, m. 1985. Statistikk for administrasjon og økonomi. Inter -American s.TIL.
- Canavos, g. 1988. Sannsynlighet og statistikk: applikasjoner og metoder. McGraw Hill.
- Devore, J. 2012. Sannsynlighet og statistikk for ingeniørfag og vitenskap. 8. Utgave. Cengage.
- Levin, r. 1988. Statistikk for administratorer. 2. Utgave. Prentice Hall.
- Walpole, r. 2007. Sannsynlighet og statistikk for ingeniørfag og vitenskap. Pearson.
- « Frihetsgrader hvordan du beregner dem, typer, eksempler
- Sannsynlighetsaksiomer, forklaring, eksempler, øvelser »