

Distribusjon F -egenskaper og øvelser løst
- 2716
- 646
- Oliver Christiansen
De distribusjon f o Fisher-Selecor Distribution er det som brukes til å sammenligne avvikene til to forskjellige eller uavhengige populasjoner, som hver følger en normalfordeling.
Distribusjonen som følger variansen til et sett med prøver av en enkelt normal populasjon er Ji-kvadratfordelingen (Χ2) av grad n-1, hvis hver av prøvene av settet har n elementer.
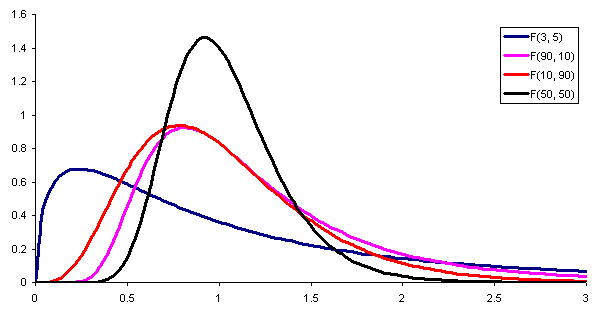
Figur 1. Her er sannsynlighetstettheten av fordelingen f med forskjellige kombinasjoner av parametere (eller frihetsgrader) for henholdsvis teller og nevner. Kilde: Wikimedia Commons. For å sammenligne avvikene til to forskjellige populasjoner, er det nødvendig å definere a statistisk, Det vil si en hjelpelig tilfeldig variabel som gjør det mulig å skille om begge populasjonene har eller ikke den samme variansen.
Denne hjelpevariabelen kan være direkte kvoten til utvalgsavvikene til hver populasjon, i hvilket tilfelle, hvis nevnte kvotient er nær enheten, er det bevist at begge populasjonene har lignende avvik.
[TOC]
Statistikken F og dens teoretiske distribusjon
Den tilfeldige variabelen f eller statistisk f foreslått av Ronald Fisher (1890 - 1962) er den som ble brukt oftere for å sammenligne variansene til to populasjoner og er definert som følger:
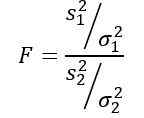
Å være s2 Prøvevaransen og σ2 Befolkningsvariansen. For å skille hver av de to populasjonsgruppene, brukes abonnement 1 og 2 henholdsvis.
Det er kjent at Ji-square-distribusjonen med (n-1) frihetsgrader er den som følger den hjelpestoffer (eller statistisk) variabel som er definert nedenfor:
X2 = (N-1) s2 / σ2.
Derfor følger statistikk F en teoretisk fordeling gitt av følgende formel:
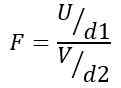
Å være ELLER Ji-kvadratfordelingen med D1 = n1 - 1 frihetsgrader for befolkning 1 og V Ji-kvadratfordelingen med D2 = n2 - 1 frihetsgrader for befolkning 2.
Kan tjene deg: vektor algebraForholdet som er definert på denne måten er en ny sannsynlighetsfordeling, kjent som distribusjon f med D1 frihetsgrader i telleren og D2 frihetsgrader i nevneren.
Gjennomsnitt, mote og varians av distribusjon F
Halv
Gjennomsnittlig fordeling F beregnes som følger:
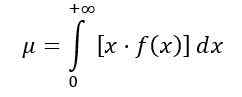
Å være f (x) Sannsynlighetstettheten av distribusjon F, som er vist i figur 1 for flere kombinasjoner av parametere eller frihetsgrader.
Du kan skrive sannsynlighetstettheten f (x) avhengig av γ -funksjonen (gamma -funksjonen):
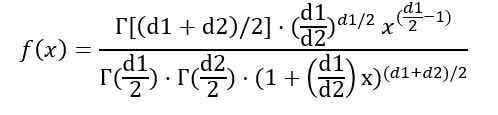
Når integralen ble angitt før, konkluderes det med at gjennomsnittet av fordelingen f med frihetsgrader (D1, D2) er: er: er: er:
μ = d2 / (d2 - 2) med d2> 2
Der det viser at gjennomsnittet er gjennomsnittet ikke avhengig av frihetsgrader D1 for telleren.
Mote
På den annen side avhenger mote av D1 og D2 og er gitt av:
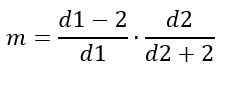
For d1> 2.
Varians av distribusjonen f
Variansen σ2 av distribusjon F beregnes ut fra integralen:
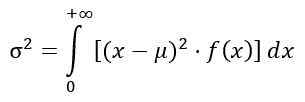
Å skaffe seg:
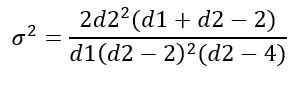
Distribusjonsstyring f
Som andre kontinuerlige sannsynlighetsfordelinger som involverer kompliserte funksjoner, gjøres distribusjon F -styring av tabeller eller ved programvare.
Distribusjonstabeller f
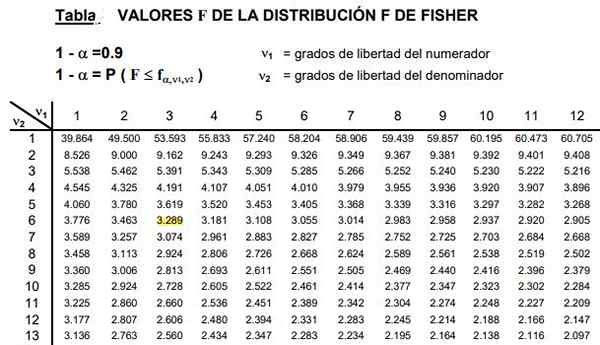 Figur 2. En del av F -distribusjonstabellen er vist, som vanligvis er veldig omfattende fordi det er en bred kombinasjon av mulige grader av frihet D1 og D2.
Figur 2. En del av F -distribusjonstabellen er vist, som vanligvis er veldig omfattende fordi det er en bred kombinasjon av mulige grader av frihet D1 og D2. Tabellene involverer de to parametrene eller graden av distribusjonsfrihet F, kolonnen indikerer graden av frihet til telleren og raden.
Kan tjene deg: ulikhet i trekanten: demonstrasjon, eksempler, løste øvelserFigur 2 viser en del av F -distribusjonstabellen for saken om en nivå av betydning 10%, det vil si α = 0,1. Verdien av f blir fremhevet når d1 = 3 og d2 = 6 med selvtillitsnivå 1- α = 0,9 som er 90%.
Programvare for distribusjon f
Når det gjelder programvaren som administrerer distribusjonen f, er det et stort utvalg, fra regnearkene som utmerke til og med spesialiserte pakker som som Minitab, SPSS og R For å nevne noen av de mest kjente.
Det skal bemerkes at geometri og matematikkprogramvare Geogebra Den har et statistisk verktøy som inkluderer hovedfordelingene, inkludert distribusjon f. Figur 3 viser fordelingen F for tilfelle D1 = 3 og D2 = 6 selvtillitsnivå 90%.
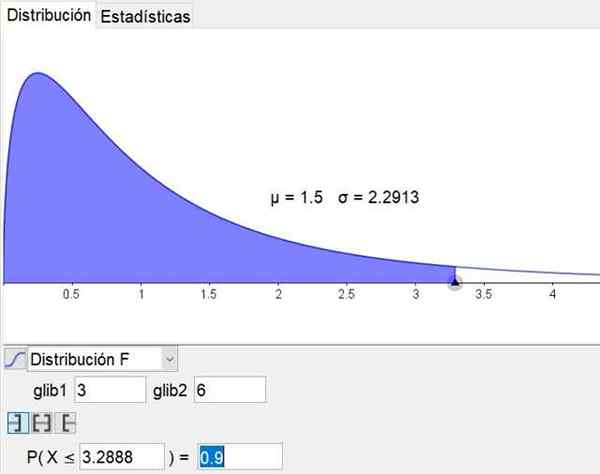 Figur 3. Distribusjonen F er vist for tilfelle D1 = 3 og D2 = 6 med 90%konfidensnivå, oppnådd gjennom det statistiske verktøyet Geogebra. Kilde: Geogebra.org
Figur 3. Distribusjonen F er vist for tilfelle D1 = 3 og D2 = 6 med 90%konfidensnivå, oppnådd gjennom det statistiske verktøyet Geogebra. Kilde: Geogebra.org Løste øvelser
Oppgave 1
Tenk på to prøver av populasjoner som har samme populasjonsvarians. Hvis prøve 1 er størrelse n1 = 5 og prøve 2 er størrelse n2 = 10, må du bestemme den teoretiske sannsynligheten for at forholdet mellom dens respektive avvik er mindre enn eller lik 2.
Løsning
Det må huskes at statistikk F er definert som:
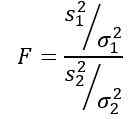
Men vi blir fortalt at befolkningsavvik er de samme, så for denne øvelsen gjelder den:
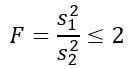
Som du vil vite den teoretiske sannsynligheten for at dette forholdet mellom prøveavvik er mindre enn eller lik 2, må vi vite området under distribusjonen F mellom 0 og 2, som kan oppnås ved tabeller eller programvare. For dette må det tas i betraktning at den nødvendige distribusjonen F har d1 = n1 - 1 = 5 - 1 = 4 og d2 = n2 - 1 = 10 - 1 = 9, det vil si distribusjonen f med frihetsgrader (4, 9).
Det kan tjene deg: serie med makt: eksempler og øvelserVed å bruke det statistiske verktøyet til Geogebra Det ble bestemt at dette området er 0.82, så det konkluderes med at sannsynligheten for at forholdet mellom prøveavvik er mindre enn eller lik 2 er 82%.
Trening 2
Det er to tynne arkproduksjonsprosesser. Variasjonen i tykkelsen må være så mye som mulig. 21 prøver av hver prosess tas. Prosessprøven har et standardavvik på 1,96 mikron, mens den for prosess B har standardavvik på 2,13 mikron. Hvilken av prosessene har lavere variabilitet? Bruk et avvisningsnivå på 5%.
Løsning
Dataene er som følger: SB = 2,13 med NB = 21; SA = 1,96 med Na = 21. Dette betyr at du må jobbe med en distribusjon F på (20, 20) frihetsgrader.
Nullhypotesen innebærer at populasjonsvariansen til begge prosessene er identisk, det vil si σa^2 / σb^2 = 1. Den alternative hypotesen vil innebære forskjellige populasjonsvarianser.
Deretter er statistikken F beregnet som: FC = (SB/SA)^2 er definert under antakelse av identiske populasjonsavvik.
Ettersom avvisningsnivået er tatt som α = 0,05, deretter α/2 = 0,025
Distribusjonen f (0.025; 20,20) = 0,406, mens F (0.975; 20,20) = 2,46.
Derfor vil nullhypotesen være sant hvis F -beregnet samsvarer: 0,406≤fc≤2,46. Ellers blir nullhypotesen avvist.
Som FC = (2,13/1,96)^2 = 1,18 er det konkludert med at FC -statistikken er i akseptområdet for nullhypotesen med en sikkerhet på 95%. Med andre ord med en sikkerhet på 95% begge produksjonsprosesser har samme populasjonsvarians.
Referanser
- F Test for uavhengighet. Gjenopprettet fra: Saylordotorg.Github.Io.
- Med Wave. Statistikk anvendt på helsevitenskap: test f. Gjenopprettet fra: Medwave.Cl.
- Sannsynligheter og statistikk. Distribusjon f. Hentet fra: Sannsynligheter Andestics.com.
- Triola, m. 2012. Elementær statistikk. 11. Utgave. Addison Wesley.
- Unam. Distribusjon f. Gjenopprettet fra: Rådgivning.Cuautitlan2.Unam.MX.
- Wikipedia. Distribusjon f. Gjenopprettet fra: er.Wikipedia.com