

Relasjonsdatabasemodellelementer, hvordan du gjør det, eksempel
- 2160
- 264
- Anders Mathisen
Han Relasjonell modell av databaser Det er en metode for å strukturere data ved bruk av relasjoner, gjennom rutenett -formede strukturer, som består av kolonner og rader. Det er det konseptuelle prinsippet for relasjonsdatabaser. Ble foreslått av Edgar f. Codd i 1969.
Siden den gang har den blitt den dominerende databasemodellen for kommersielle applikasjoner, sammenlignet med andre databasemodeller, for eksempel hierarkisk, nettverk og objekt.
Kilde: Pixabay.com Codd hadde ingen anelse om det ekstremt viktige og innflytelsesrike som ville være hans arbeid som plattform for relasjonsdatabaser. De fleste er veldig kjent med det fysiske uttrykket til et forhold i en database: tabellen.
Relasjonsmodellen er definert som databasen som gjør det mulig å gruppere dataelementene i en eller flere uavhengige tabeller, som kan være relatert til hverandre ved å bruke vanlige felt til hver relatert tabell.
[TOC]
Database ledelse
En database ligner et regneark. Forholdene som kan opprettes mellom tabellene tillater imidlertid en relasjonsdatabase for å lagre en stor mengde data effektivt, som kan gjenopprettes effektivt.
Hensikten med den relasjonelle modellen er å gi en deklarativ metode for å spesifisere data og konsultasjoner: brukere erklærer direkte hvilken informasjon databasen inneholder og hvilken informasjon du vil ha av den.
På den annen side lar de programvaren til databasestyringssystemet være ansvarlig for å beskrive datastrukturer for lagrings- og gjenopprettingsprosedyre for å svare.
De fleste relasjonsdatabaser bruker SQL -språket for konsultasjon og definisjon av dataene. Det er for øyeblikket mange relasjonsdatabaseadministrasjonssystemer eller RDBMS (Relational Data Base Management System), for eksempel Oracle, IBM DB2 og Microsoft SQL Server.
Egenskaper og elementer
- Alle data er konseptuelt representert som en ordnet disposisjon av data i rader og kolonner, kalt forhold eller tabell.
- Hver tabell må ha en header og en kropp. Overskriften er ganske enkelt kolonnelisten. Kroppen er settet med data som fyller bordet, organisert i rader.
- Alle verdier er stigninger. Det vil si i en gitt plassering av rad/kolonne i tabellen, er det bare en unik verdi.
-Gjenstander
Følgende figur viser en tabell med navnene på dets grunnleggende elementer, som utgjør en fullstendig struktur.
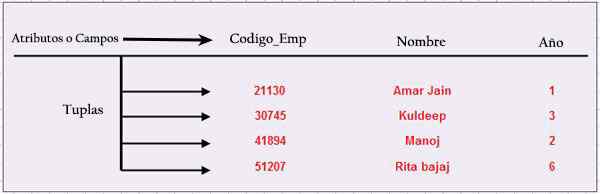
Tupla
Hver rad med data er en tupla, også kjent som registrering. Hver rad er en n-tupla, men "n-" utelukkes generelt.
Kolonne
Hver kolonne i en tupla kalles attributt eller felt. Kolonnen representerer settet med verdier som et spesifikt attributt kan ha.
Ledetråd
Hver rad har en eller flere kolonner som kalles tabellen. Denne kombinerte verdien er unik for alle radene i et bord. Gjennom denne nøkkelen vil hver tupla bli identifisert på en entydig måte. Det vil si at nøkkelen ikke kan dupliseres. Det kalles primærnøkkel.
På den annen side er en ekstern eller sekundær nøkkel feltet i en tabell som refererer til den primære nøkkelen til en annen tabell. Det brukes til å referere til primærtabellen.
-Integritetsregler
Når du designer den relasjonelle modellen, er noen forhold som må oppfylles i databasen, kalt integritetsregler definert.
Kan tjene deg: Makrokompatører: Historie, egenskaper, bruksområder, eksemplerNøkkelintegritet
Den primære nøkkelen må være unik for alle tuples og kan ikke ha nullverdien (null). Ellers vil du ikke kunne identifisere raden utelukkende.
For en nøkkel sammensatt av flere kolonner kan ingen av disse kolonnene inneholde null.
Referanseintegritet
Hver verdi av en ekstern nøkkel må sammenfalle med en verdi av den primære nøkkelen i den refererte eller primære tabellen.
I den sekundære tabellen kan bare en rad settes inn med en ekstern nøkkel hvis den verdien eksisterer i en primærtabell.
Hvis verdien av nøkkelendringene i primærtabellen, for å oppdatere eller eliminere raden, må alle radene i sekundære tabeller med denne eksterne nøkkelen oppdateres eller elimineres deretter.
Hvordan lage en relasjonell modell?
-Samle data
De nødvendige dataene for å lagre dem i databasen må samles inn. Disse dataene er delt inn i forskjellige tabeller.
En passende datatype må velges for hver kolonne. For eksempel: Hele tall, flytende punkttall, tekst, dato osv.
-Definer primærnøkler
For hver tabell må du velge en kolonne (eller få kolonner) som en primærnøkkel, som unikt identifiserer hver rad i tabellen. Den primære nøkkelen brukes også til å referere til andre tabeller.
-Lag forhold mellom tabeller
En database bestående av uavhengige og ikke -relaterte tabeller har lite formål.
Det mest avgjørende aspektet i utformingen av en relasjonsdatabase er å identifisere forholdene mellom tabellene. Forholdstypene er:
En for mange
I en "klasser" -database kan en lærer undervise i null eller flere klasser, mens en klasse blir undervist av en enkelt lærer. Denne typen forhold er kjent som en for mange.
Dette forholdet kan ikke representeres i en enkelt tabell. I databasen "Klasseoppføring" kan du ha en tabell som heter Teachers, som lagrer informasjon om lærere.
For å lagre klassene som er undervist av hver lærer, kan det opprettes ytterligere kolonner, men et problem vil møte: hvor mange kolonner som oppretter.
På den annen side, hvis du har et bord som heter klasser, lagrer den informasjon om en klasse, kan det opprettes ytterligere kolonner for å lagre informasjon om læreren.
Imidlertid, som en lærer kan undervise i mange klasser, vil dataene hans bli doblet i mange rekker i klassen.
Design to bord
Derfor må to tabeller utformes: en klassetabell for å lagre informasjon om klasser, med_idklasse som hovednøkkel, og et mesterbord for å lagre informasjon om lærere, med lærer_id som hovednøkkel.
Da kan du opprette forholdet en til mange som lagrer den primære nøkkelen til masterbordet (master_id) i klassenes tabell, som illustrert nedenfor.
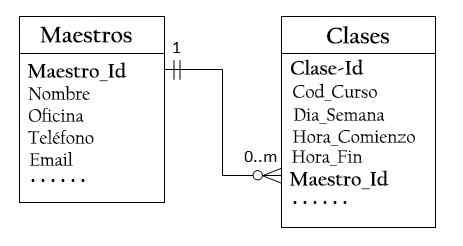
Master_id -kolonnen i klassetabellen er kjent som ekstern eller sekundærnøkkel.
For hver master_id -verdi i hovedtabellen kan det være null eller flere rader i klassen. For hver klasse_idverdi i klassenes tabell er det bare en rad i masterbordet.
Mange for mange
I en "produktsalg" -database kan en kundes ordre inneholde flere produkter, og et produkt kan vises i flere bestillinger. Denne typen forhold er kjent som mange for mange.
Det kan tjene deg: IKT (informasjons- og kommunikasjonsteknologier)Du kan starte databasen "Produktsalg" med to tabeller: produkter og bestillinger. Produkttabellen inneholder informasjon om produktene, med produkt som en primærnøkkel.
På den annen side inneholder ordrene kundebestillinger, med forespørsel som primærkode.
Du kan ikke lagre produktene som etterspørres i det bestilte tabellen, siden det ikke er kjent hvor mange kolonner som reserverer for produktene. Bestillinger kan heller ikke lagres i tabellproduktene av samme grunn.
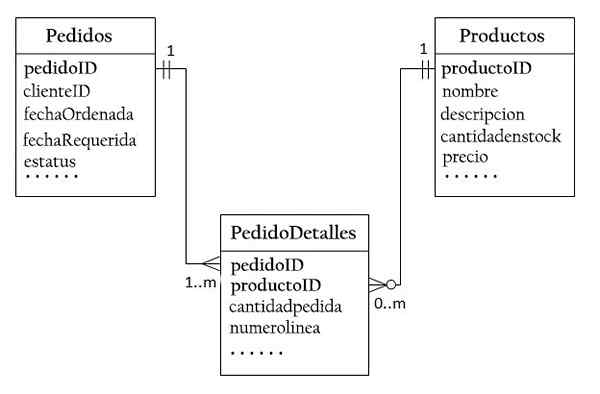
For å innrømme et forhold mange for mange, er det nødvendig å lage en tredje tabell, kjent som Union Table (ber om), der hver rad representerer et element i en bestemt ordre.
For den anmodende tabellen består den primære tasten av to kolonner: rekkefølge og produkt, identifisere hver rad hver rad.
De forespurte og produktkolonnene i forespørselen om metodene brukes til å referere til ordrene og produktene. Derfor er de også eksterne nøkler til forespørselen om forespørselen.
En etter en
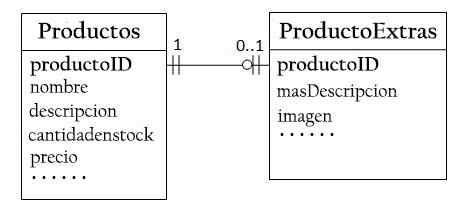
I databasen "Produktsalg" kan et produkt ha valgfri informasjon, som en ekstra beskrivelse og dets image. Hold det inne i produktene vil generere mange tomme mellomrom.
Derfor kan du opprette en annen tabell (extExts -produkt) for å lagre valgfrie data. Bare en post for produkter med valgfrie data vil bli opprettet.
De to tabellene, produktene og produktet, har et forhold. For hver rad i produkttabellen er det en maksimal rad i produktet Tablexts. Det samme produktet skal brukes som hovednøkkel for begge tabellene.
Fordeler
Strukturell uavhengighet
I den relasjonelle databasemodellen påvirker ikke endringer i databasestrukturen tilgang til data.
Når det er mulig å gjøre endringer i strukturen i databasen uten å påvirke DBMS -muligheten til å få tilgang til dataene, kan det sies at strukturell uavhengighet er oppnådd.
Konseptuell enkelhet
Den relasjonelle databasemodellen er enda enklere på konseptuelt nivå enn den hierarkiske modellen eller databasenettverket.
Siden den relasjonelle databasemodellen slipper designeren fra detaljene om fysisk lagring av dataene, kan designerne konsentrere seg om databasenes logiske visning av databasen.
Enkel design, implementering, vedlikehold og bruk
Den relasjonelle databasemodellen oppnår både uavhengighetens uavhengighet og uavhengigheten til strukturen, noe som gjør design, vedlikehold, administrasjon og bruk av databasen mye enklere enn de andre modellene.
Ad-hoc konsultasjonskapasitet
Tilstedeværelsen av en veldig kraftig, fleksibel og enkel å bruke konsultasjonskapasitet er en av hovedårsakene til den enorme populariteten til databasen Relational Base Model.
Konsultasjonsspråket til den relasjonelle databasemodellen, kalt strukturert konsultasjonsspråk eller SQL, gjør at ad-hoc-spørsmål går i oppfyllelse. SQL er et fjerde generasjons språk (4GL).
En 4GL lar brukeren spesifisere hva som skal gjøres, uten å spesifisere hvordan det skal gjøres. Med SQL -brukere kan således spesifisere hvilken informasjon de vil ha og legge igjen detaljene om hvordan du får informasjonen til databasen.
Ulemper
Maskinvareutgifter
Den relasjonelle databasemodellen skjuler kompleksitetene i implementeringen og detaljene om fysisk lagring av brukerdataene.
Kan tjene deg: Hva er G -koder? (Med eksempel)For å gjøre dette, trenger relasjonsdatabasesystemer datamaskiner med kraftigere maskinvare og lagring.
Derfor trenger RDBMS kraftige maskiner for å fungere uten problemer. Siden prosessorkraften til moderne datamaskiner øker i et eksponentielt tempo, er imidlertid behovet for mer prosessorkraft i det nåværende scenariet lenger et veldig stort problem.
Design Lett kan føre til dårlig design
Den relasjonsdatabasen er enkel å designe og bruke. Brukere trenger ikke å vite de komplekse detaljene om fysisk lagring av dataene. De trenger ikke å vite hvordan data virkelig lagres for å få tilgang til dem.
Denne utformingen og brukeren kan føre til utvikling og implementering av veldig dårlig utformede databasestyringssystemer. Siden databasen er effektiv, vil ikke disse designens ineffektivitet komme fram når databasen er designet, og når det bare er en liten mengde data.
Når databasen vokser, vil de dårlig utformede databasene bremse systemet og forårsake en nedbrytning av dataytelsen og korrupsjonen.
Fenomenet "Informasjonsøyene"
Som sagt før, er relasjonsdatabasesystemer enkle å implementere og bruke. Dette vil skape en situasjon der for mange mennesker eller avdelinger vil lage sine egne databaser og applikasjoner.
Disse informasjonsøyene vil unngå integrering av informasjon, noe som er essensielt for organisasjonens flytende og effektive funksjon.
Disse individuelle databasene vil også skape problemer som datainkonsekvens, dobbeltdisponering, dataredundans, etc.
Eksempel
Anta at en database består av supplerende tabeller, stykker og forsendelser. Strukturen til tabellene og noen eksempler på poster er presentert nedenfor:
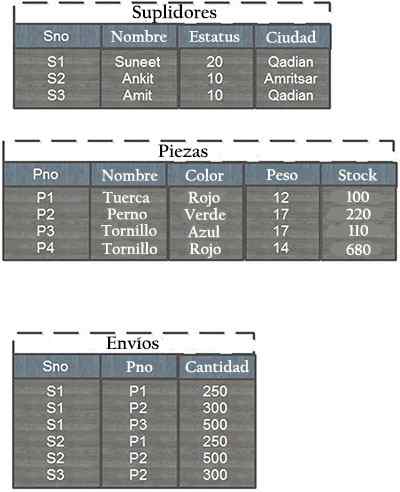
Hver rad i forsyningstabellen identifiseres av et unikt leverandørnummer (SNO), som unikt identifiserer hver rad i tabellen. På samme måte har hvert stykke et unikt delnummer (PNO).
I tillegg kan det ikke være mer enn en forsendelse for en gitt leverandør / stykke kombinasjon i skipstabellen, siden denne kombinasjonen er den primære fraktnøkkelen, som fungerer som et unionstabell, ettersom mange er et forhold til mange for mange.
Forholdet mellom tabellene og forsendelsene er gitt ved å ha felles PNO -feltet (stykkenummer) og forholdet mellom leverandører og forsendelser oppstår fra å ha felles SNO -feltet (leverandørnummer).
Analyse av forsendelsesbordet kan fås som informasjon som blir sendt totalt 500 nøtter fra Suneet- og Ankit -leverandørene, 250 hver.
På samme måte ble 1 sendt.100 bolter totalt fra tre forskjellige leverandører. 500 blå skruer ble sendt fra Suneet -leverandøren. Det er ingen røde skrueforsendelser.
Referanser
- Wikipedia, The Free Encyclopedia (2019). Relasjonell modell. Hentet fra: i.Wikipedia.org.
- Ravepedia (2019). Relasjonell modell. Hentet fra: ravepedia.com.
- Diesh Thakur (2019). Relasjonell modell. Ecomputer -notater. Hentet fra: ecomputernotes.com.
- Geeks for geeks (2019). Relasjonell modell. Hentet fra: geeksforgeeks.org.
- Nanyang Technological University (2019). En hurtigskartopplæring om relasjonsdatabasedesign. Hentet fra: ntu.Edu.Sg.
- Adrienne Watt (2019). Kapittel 7 Den relasjonelle datamodellen. BC åpne lærebøker. Hentet fra: OpenTextBc.Ac.
- Toppr (2019). Relasjonsdatabaser og skjemaer. Hentet fra: toppr.com.
- « Operasjonsforskning Hva er det for, modeller, applikasjoner
- Vanadio historie, egenskaper, struktur, bruker »